Puppeteer 라이브러리로 웹 스크래핑하는 방법

Puppeteer 라이브러리로 웹 스크립핑하는 방법에 대해 설명하는 페이지입니다.
Environment
- Node.js v20.11.1
- express v4.21.0
- Puppeteer-core v23.5.3
목차
- 개요
- Puppeteer란?
- Puppeteer의 주요 기능
- Step 1 - Puppeteer 설치하기
- Step 2 - 웹 스크래핑 코드 작성하기
- Step 3 - 웹 스크래핑하기
- 참고 자료
- Comments
개요
이번 글에서는 Puppeteer 라이브러리를 활용하여 웹 스크래핑(Web Scraping)하는 방법에 대해 설명하겠습니다.
Puppeteer란?
Puppeteer 라이브러리는 Headless Chrome 또는 Headless Chromium 브라우저를 제어하기 위한 Node.js 라이브러리입니다. Puppeteer는 주로 웹 스크래핑, UI 테스트 자동화, 스크린샷 및 PDF 생성 등 다양한 작업에 활용됩니다. Puppeteer는 기본적으로 백그라운드에서 headless(= No visible UI)로 동작하지만, 원한다면 headless 모드를 비활성화해서 실제 브라우저 창을 띄워서 동작하도록 할 수 있습니다.
Puppeteer의 주요 기능
Puppeteer의 주요 기능은 다음과 같습니다.
HeadlessPuppeteer는 headless 모드로 동작할 수 있습니다. UI가 없이 동작할 수 있으므로 터미널이나 CLI(Command-Line Interface) 환경에서도 동작할 수 있습니다.웹 스크래핑JavaScript로 렌더링된 페이지를 포함한 모든 웹 페이지에서 데이터를 추출할 수 있습니다.
UI 테스트 자동화클릭, 타이핑, 스크롤 등 사용자가 웹 사이트와 상호작용하는 과정을 자동화할 수 있습니다.
스크린샷 또는 PDF 생성특정 웹 페이지의 스크린샷 또는 PDF를 생성할 수 있습니다.
크롤링여러 페이지를 탐색하고 링크를 따라가면서 데이터를 수집하는 웹 크롤러를 구현할 수 있습니다.
폼 제출 및 파일 업로드웹 폼을 자동으로 채우고 제출하거나 파일을 업로드하는 등의 작업을 수행할 수 있습니다.
SPA 지원Single Page Application(SPA)에서 네트워크 요청이 완료된 이후에 페이지를 처리하는 기능을 지원합니다.
Step 1 - Puppeteer 설치하기
Puppeteer를 설치하기 위해선 다음 두 가지 명령어 중 하나를 입력하면 됩니다.
npm install puppeteer
또는
npm install puppeteer-core
puppeteer-core 라이브러리는 Puppeteer 패키지의 경량화된 버전으로, Chrome 또는 Chromium 브라우저를 포함하지 않은 Puppeteer 라이브러리입니다. puppeteer 패키지를 설치하면 자동으로 최신 버전의 Chrome for Testing(~170MB macOS, ~282MB Linux, ~280MB Windows)과 chrome-headless-shell 바이너리를 설치하게 됩니다. 반면에 puppeteer-core 패키지를 설치하는 경우 브라우저를 설치하지 않으며 이미 설치된 로컬 브라우저나 원격 Google Chrome/Chromium 인스턴스를 제어하게 됩니다.
puppeteer와 puppeteer-core의 차이점을 정리하면 다음과 같습니다.
puppeteer- Chrome/Chromium 브라우저를 함께 설치합니다.
- 사용자가 별도로 브라우저를 설치할 필요 없이 Puppeteer 스크립트를 실행할 수 있습니다.
- 브라우저를 함께 설치하므로 파일 크기가 더 크며, 설치 시간도 더 오래 걸립니다.
puppeteer-core- Chrome/Chromium 브라우저를 설치하지 않습니다. 그러므로 이미 설치된 Chrome 또는 Chromium 브라우저를 사용해야 합니다.
- Puppeteer가 브라우저와 상호작용하는 API만 제공하므로, 패키지가 훨씬 가볍습니다.
- 브라우저를 제어하기 위한 launch 옵션을 직접 설정해야 합니다.
위와 같은 차이점을 비교하였을 때, puppeteer-core를 사용하는 경우는 다음과 같습니다.
- 이미 Chrome 또는 Chromium이 설치되어 있는 경우
- 특정 버전의 Chrome/Chromium을 제어하고자 할 때
- 원격 브라우저에 연결하고자 할 때
- 브라우저를 스스로 제어하고자 할 때
- 클라우드 환경이나 서버 환경에서 Puppeteer를 사용할 때, 브라우저 다운로드로 인한 설치 시간을 줄이고 싶을 때
저의 경우 개발 환경에 이미 Chrome이 설치되어 있기 때문에 파일 크기를 줄이기 위해 puppeteer-core를 설치하였습니다. 또한 제가 자주 사용하는 Raspberry Pi의 경우 Raspberry Pi OS Full 버전이 설치되어 있으며, Chromium이 기본적으로 설치되어 있기 때문에 브라우저 설치가 불필요하므로 puppeteer-core를 선택하였습니다.
Step 2 - 웹 스크래핑 코드 작성하기
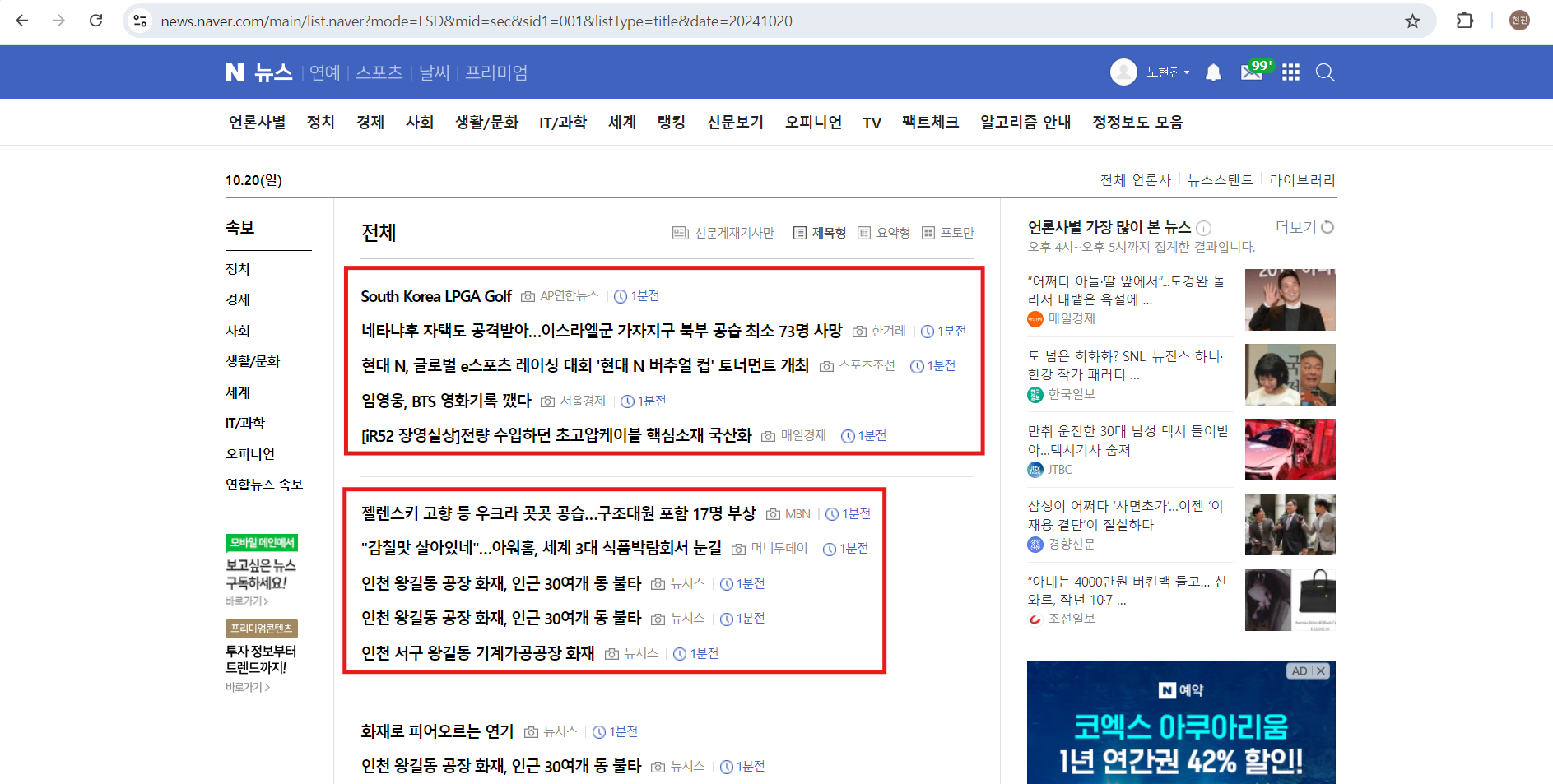
이번 글에서는 웹 스크래핑 예시로 네이버 뉴스 데이터를 추출해 보겠습니다. 다음 두 웹 페이지에서 언론사별 뉴스와 최신 뉴스 데이터를 추출하겠습니다.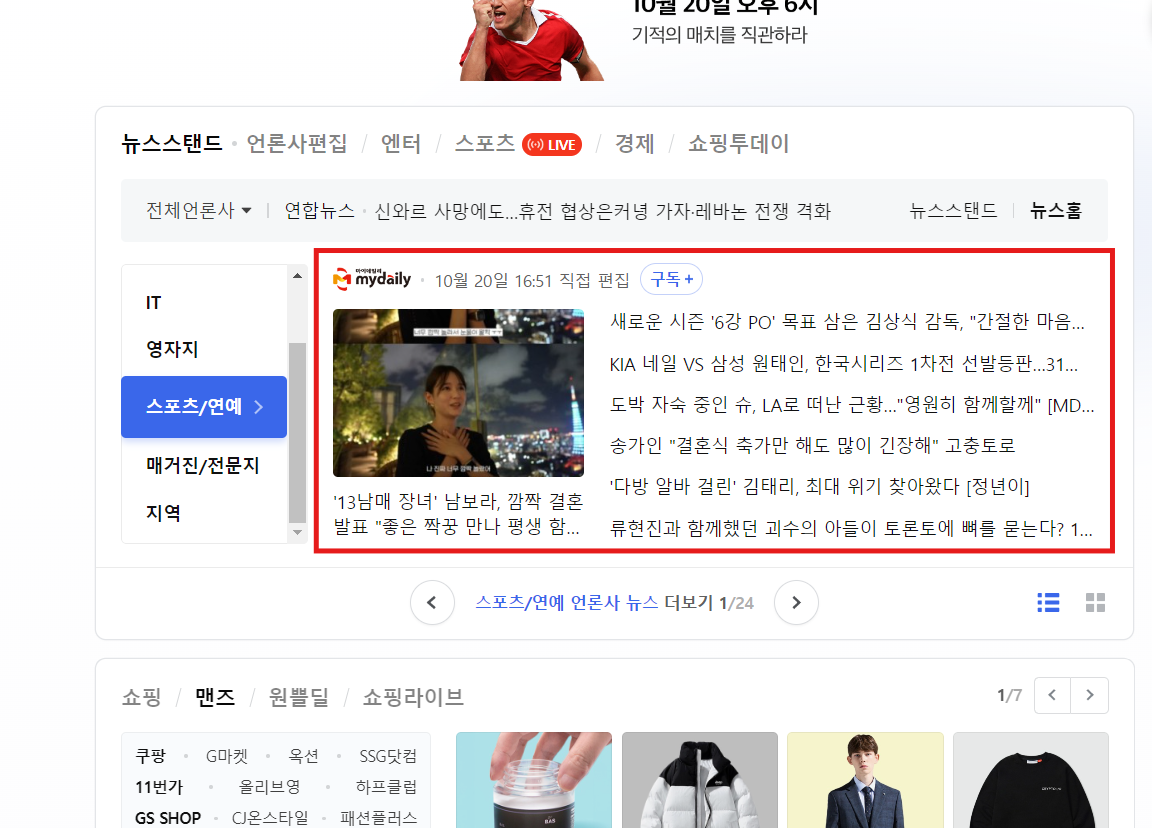
브라우저 실행하기
먼저 다음과 같이 브라우저를 실행하고 페이지를 여는 코드를 작성합니다.
import puppeteer, { executablePath, Page } from "puppeteer-core";
export const scraping = async () => {
// Launch the browser and open a new blank page.
// 브라우저 실행
const browser = await puppeteer.launch({
headless: false, // false인 경우 headless 모드를 비활성화해서 실제 브라우저 창을 띄워서 동작합니다.
executablePath: executablePath("chrome"), // Puppeteer가 로컬 시스템에서 Chrome 브라우저를 찾아 실행
});
// 새로운 페이지 열기
const page = await browser.newPage();
// 언론사별 뉴스 데이터
const pressList = await getPressList(page);
// 최신 뉴스 데이터
const latestNewsList = await getLatestNewsList(page);
// 브라우저 종료
await browser.close();
return { pressList, latestNewsList };
};
위의 코드의 puppeteer.launch 부분의 headless는 headless 모드를 설정하는 부분입니다. false로 지정하는 경우 headless 모드를 해제하여 화면에 실제 브라우저 창을 띄워서 동작하게 됩니다. 저의 경우 웹 스크래핑 실제 동작 예시를 설명하기 위해 false로 설정하였습니다. 또한 executablePath 부분은 puppeteer-core를 사용하는 경우 반드시 선언해야 하는 코드로, puppeteer가 동작할 때 사용할 브라우저를 지정하는 부분입니다. 위의 코드와 같이 executablePath("chrome")을 지정하면 Puppeteer가 로컬 시스템에서 Chrome 브라우저를 찾아 실행하게 됩니다.
참고로 puppeteer-core를 Raspberry Pi에서 사용하는 경우, Chromium이 존재하는 경로를 지정하면 됩니다. 일반적으로 Raspberry Pi의 Chromium 실행 파일은 usr/bin/chromium-browser 경로에 존재하므로, 다음과 같이 경로를 명시하여 Puppeteer를 실행하면 됩니다. Chromium이 설치되어 있지 않는 경우 다음 명령어를 실행하면 됩니다.
sudo apt update
sudo apt install chromium-browser
const browser = await puppeteer.launch({
headless: true, // Raspberry Pi에서 리소스 절약을 위해 headless 모드를 사용합니다.
executablePath: "usr/bin/chromium-browser", // Chromium 경로를 지정합니다.
});
언론사별 뉴스 데이터 가져오기
다음과 같이 언론사별 뉴스 데이터를 스크래핑하는 코드를 작성합니다.
const getPressList = async (page: Page) => {
// Navigate the page to a URL.
await page.goto("https://www.naver.com");
// Set screen size.
// await page.setViewport({ width: 1080, height: 1024 });
// Wait and click on first result
const searchResultSelector =
".ContentPagingView-module__btn_view_list___j7eNR";
await page.waitForSelector(searchResultSelector);
await page.click(searchResultSelector);
const pressList: {
category: string;
pressImage: string;
pressName: string;
lastModifiedAt: string;
mainNewsImage: string;
mainNewsTitle: string;
mainNewsLink: string;
subNewsList: {
subNewsTitle: string;
subNewsLink: string;
}[];
}[] = [];
for (let i = 0; i < 244; i++) {
await new Promise((resolve) => setTimeout(resolve, 300));
const category = await (
await page.waitForSelector(".ContentPagingView-module__point___U2tUD")
)?.evaluate(
(element) => (element as HTMLSpanElement).innerText.split(" ")[0]
);
const pressInfo = await (
await page.waitForSelector(".MediaNewsView-module__news_logo___LwMpl img")
)?.evaluate((element) => ({
pressImage: (element as HTMLImageElement).src,
pressName: (element as HTMLImageElement).alt,
}));
const lastModifiedAt = await (
await page.waitForSelector(".MediaNewsView-module__time___fBQhP")
)?.evaluate((element) => (element as HTMLSpanElement).innerText);
const mainNewsImage = await (
await page.waitForSelector(".ImgView-module__content_img___QA0gl img")
)?.evaluate((element) => (element as HTMLImageElement).src);
const mainNewsData = await (
await page.waitForSelector(".MediaNewsView-module__desc_title___IObEv")
)?.evaluate((element) => ({
mainNewsTitle: (element as HTMLAnchorElement).innerText.slice(0, 100),
mainNewsLink: (element as HTMLAnchorElement).href,
}));
const subNewsList = await (
await page.waitForSelector(".MediaNewsView-module__desc_list___uQ3r1")
)?.evaluate((element) =>
Array.from(
element.querySelectorAll(".MediaNewsView-module__link_item___x0z7x")
).map((value) => ({
subNewsTitle: (value as HTMLAnchorElement).innerText.slice(0, 100),
subNewsLink: (value as HTMLAnchorElement).href,
}))
);
if (
category &&
pressInfo &&
lastModifiedAt &&
mainNewsImage &&
mainNewsData &&
subNewsList
) {
pressList.push({
category,
pressImage: pressInfo?.pressImage,
pressName: pressInfo?.pressName,
lastModifiedAt,
mainNewsImage,
mainNewsTitle: mainNewsData?.mainNewsTitle,
mainNewsLink: mainNewsData?.mainNewsLink,
subNewsList,
});
}
await page.click(".ContentPagingView-module__btn_next___ZBhby");
}
return pressList;
};
위의 코드에서 waitForSelector는 지정한 선택자가 DOM 나타날 때까지 기다리는 함수입니다. 페이지가 완전히 로드되지 않았거나, 동적으로 렌더링되는 요소를 너무 빨리 가져오려고 하면 데이터를 가져오는데 실패할 수 있습니다. 따라서 Puppeteer의 waitForSelector를 사용하여 특정 DOM 요소가 완전히 렌더링된 후에 데이터를 가져오도록 설정합니다. 또한 evaluate 함수는 브라우저 환경, 즉 웹 페이지 내에서 자바스크립트 코드를 실행하여 특정 DOM 요소의 데이터를 가져오는데 사용됩니다.
최신 뉴스 데이터 가져오기
최신 뉴스 데이터를 가져오는 코드는 언론사별 뉴스 데이터를 가져오는 코드와 크게 다르지 않습니다. 다음과 같이 해당 웹 페이지로 이동한 후 웹 스크래핑을 진행하면 됩니다.
const getLatestNewsList = async (page: Page) => {
await page.goto(
"https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=001&listType=title"
);
const latestNewsList = await (
await page.waitForSelector(".list_body")
)?.evaluate((element) =>
Array.from(element.querySelectorAll(".type02"))
.slice(0, 2)
.map((value) =>
Array.from(value.querySelectorAll("li")).map((liElement) => ({
latestNewsTitle:
(liElement as HTMLLIElement)
.querySelector("a")
?.innerText.slice(0, 100) ?? "",
latestNewsLink:
(liElement as HTMLLIElement).querySelector("a")?.href ?? "",
pressName:
(
(liElement as HTMLLIElement).querySelector(
".writing"
) as HTMLSpanElement
).innerText ?? "",
}))
)
);
return latestNewsList!;
};
전체 코드
전체 코드는 다음과 같습니다.
import puppeteer, { executablePath, Page } from "puppeteer-core";
export const scraping = async () => {
// Launch the browser and open a new blank page.
// 브라우저 실행
const browser = await puppeteer.launch({
headless: false, // false인 경우 headless 모드를 비활성화해서 실제 브라우저 창을 띄워서 동작합니다.
executablePath: executablePath("chrome"), // Puppeteer가 로컬 시스템에서 Chrome 브라우저를 찾아 실행
});
// 새로운 페이지 열기
const page = await browser.newPage();
// 언론사별 뉴스 데이터
const pressList = await getPressList(page);
// 최신 뉴스 데이터
const latestNewsList = await getLatestNewsList(page);
// 브라우저 종료
await browser.close();
return { pressList, latestNewsList };
};
const getPressList = async (page: Page) => {
// Navigate the page to a URL.
await page.goto("https://www.naver.com");
// Set screen size.
// await page.setViewport({ width: 1080, height: 1024 });
// Wait and click on first result
const searchResultSelector =
".ContentPagingView-module__btn_view_list___j7eNR";
await page.waitForSelector(searchResultSelector);
await page.click(searchResultSelector);
const pressList: {
category: string;
pressImage: string;
pressName: string;
lastModifiedAt: string;
mainNewsImage: string;
mainNewsTitle: string;
mainNewsLink: string;
subNewsList: {
subNewsTitle: string;
subNewsLink: string;
}[];
}[] = [];
for (let i = 0; i < 244; i++) {
await new Promise((resolve) => setTimeout(resolve, 300));
const category = await (
await page.waitForSelector(".ContentPagingView-module__point___U2tUD")
)?.evaluate(
(element) => (element as HTMLSpanElement).innerText.split(" ")[0]
);
const pressInfo = await (
await page.waitForSelector(".MediaNewsView-module__news_logo___LwMpl img")
)?.evaluate((element) => ({
pressImage: (element as HTMLImageElement).src,
pressName: (element as HTMLImageElement).alt,
}));
const lastModifiedAt = await (
await page.waitForSelector(".MediaNewsView-module__time___fBQhP")
)?.evaluate((element) => (element as HTMLSpanElement).innerText);
const mainNewsImage = await (
await page.waitForSelector(".ImgView-module__content_img___QA0gl img")
)?.evaluate((element) => (element as HTMLImageElement).src);
const mainNewsData = await (
await page.waitForSelector(".MediaNewsView-module__desc_title___IObEv")
)?.evaluate((element) => ({
mainNewsTitle: (element as HTMLAnchorElement).innerText.slice(0, 100),
mainNewsLink: (element as HTMLAnchorElement).href,
}));
const subNewsList = await (
await page.waitForSelector(".MediaNewsView-module__desc_list___uQ3r1")
)?.evaluate((element) =>
Array.from(
element.querySelectorAll(".MediaNewsView-module__link_item___x0z7x")
).map((value) => ({
subNewsTitle: (value as HTMLAnchorElement).innerText.slice(0, 100),
subNewsLink: (value as HTMLAnchorElement).href,
}))
);
if (
category &&
pressInfo &&
lastModifiedAt &&
mainNewsImage &&
mainNewsData &&
subNewsList
) {
pressList.push({
category,
pressImage: pressInfo?.pressImage,
pressName: pressInfo?.pressName,
lastModifiedAt,
mainNewsImage,
mainNewsTitle: mainNewsData?.mainNewsTitle,
mainNewsLink: mainNewsData?.mainNewsLink,
subNewsList,
});
}
await page.click(".ContentPagingView-module__btn_next___ZBhby");
}
return pressList;
};
const getLatestNewsList = async (page: Page) => {
await page.goto(
"https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=001&listType=title"
);
const latestNewsList = await (
await page.waitForSelector(".list_body")
)?.evaluate((element) =>
Array.from(element.querySelectorAll(".type02"))
.slice(0, 2)
.map((value) =>
Array.from(value.querySelectorAll("li")).map((liElement) => ({
latestNewsTitle:
(liElement as HTMLLIElement)
.querySelector("a")
?.innerText.slice(0, 100) ?? "",
latestNewsLink:
(liElement as HTMLLIElement).querySelector("a")?.href ?? "",
pressName:
(
(liElement as HTMLLIElement).querySelector(
".writing"
) as HTMLSpanElement
).innerText ?? "",
}))
)
);
return latestNewsList!;
};
Step 3 - 웹 스크래핑하기
위에서 작성한 웹 스크래핑 코드를 통해 웹 스크래핑한 결과는 다음과 같습니다.